by  WANG
WANG

C/C++語言的語法擁有其它語言所沒有的靈活性,這種靈活性帶來了代碼效率的提升,但相應也使得代碼編寫具有很大的隨意性,另外C/C++編譯器不進行強制類型檢查,也不做任何邊界檢查,這就增加了代碼中存在隱患的可能性。如果能夠在代碼提交測試之前發現這些潛在的錯誤,就能夠極大地減輕測試人員的壓力,減少軟件項目的除錯成本,可是傳統的C/C++編譯器對此已經無能為力,這個任務只能由專用的代碼檢查工具完成,PC-Lint因此應運而生。
PC-Lint是GIMPEL SOFTWARE公司開發的C/C++軟件代碼靜態分析工具,它的全稱是PC-Lint for C/C++,PC-Lint能夠在Windows、MS-DOS和OS/2平臺上使用,以二進制可執行文件的形式發布。PC-lint在全球擁有廣泛的客戶群,許多大型的軟件開發組織都把PC-Lint檢查作為代碼走查的第一道工序。 PC-Lint不僅能夠對程序進行全局分析,識別沒有被適當檢驗的數組下標,報告未被初始化的變量,警告使用空指針以及冗余的代碼,還能夠有效地幫你提出許多程序在空間利用、運行效率上的改進點。
通過下面的例子就可以看出PC-Lint工具的強大功能:
1:
2:char *report( int m, int n, char *p )
3:{
4: int result;
5: char *temp;
6: long nm;
7: int i, k, kk;
8: char name[11] = "Joe Jakeson";
9:
10: nm = n * m;
11: temp = p == "" ? "null" : p;
12: for( i = 0; i<m; I++ ) {
14: k++;
15: kk = i;
16: }
17:
18: if( k== 1 ) result = nm;
19: else if( kk > 0 ) result = 1;
20: else if( kk < 0 ) result = -1;
21:
22: if( m == result ) return( temp );
23: else return( name );
24:}
這是一段C代碼,可以通過大多數常見的C語言編譯器的檢查,但是PC-Lint能夠發現其中的錯誤和潛在的問題:第8行向name數組賦值時丟掉了結尾的null字符,第10行的乘法精度會失準,即使考慮到long比int的字長更長,由于符號位的原因仍然會造成精度失準,第11行的比較有問題,第14行的變量k沒有初始化,第15行的kk可能沒有被初始化,第22行的result也有可能沒有被初始化,第23行返回的 是一個局部對象的地址。
對于一個小程序,多數程序員都能夠及時發現上面出現的錯誤,但是從一個擁有成千上萬行代碼的大型軟件中找出這些瑕疵將是一項煩瑣的工作,而且沒有人可以保證能找出所有的這類問題。如果使用PC-Lint,只需通過一次簡單的編譯就可以檢查出這些錯誤,這將節省了大量的開發時間。從某種意義上說。PC- Lint是一種更加嚴格的編譯器,它除了可以檢查出一般的語法錯誤外,還可以檢查出那些雖然符合語法要求,但很可能是潛在的、不易發現的錯誤。
PC-Lint能夠檢查出很多語法錯誤和語法上正確的邏輯錯誤,PC-Lint為大部分錯誤消息都分配了一個錯誤號,編號小于1000的錯誤號是分配給C 語言的,編號大于1000的錯誤號則用來說明C++的錯誤消息。下表列出了PC-Lint告警消息的詳細分類:
| 錯誤說明 | C |
| 語法錯誤 | 1-199 |
| 內部錯誤 | 200-299 |
| 致命錯誤 | 300-399 |
| 告警 | 400-699 |
| 消息 | 700-800 |
| 可選信息 | 900-999 |
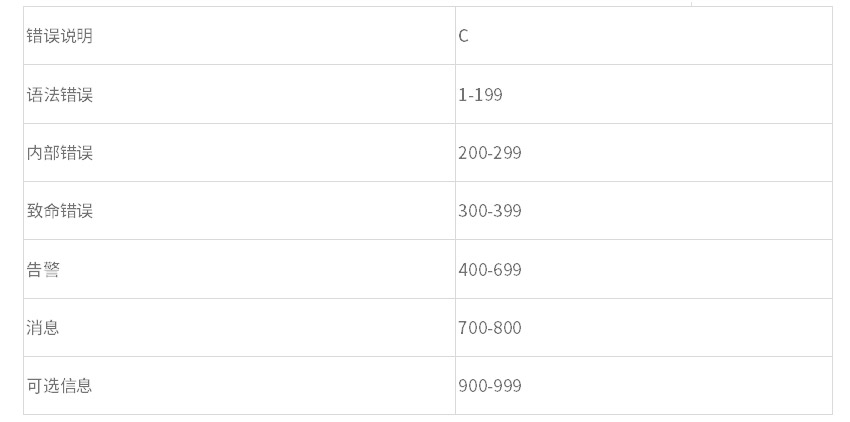
以 C語言為例,其中的編號1-199指的是一般編譯器也會產生的語法錯誤;編號200-299是PC-Lint程序內部的錯誤,這類錯誤不會出現在代碼中的;編號300-399指的是由于內存限制等導致的系統致命錯誤。編號400-999中出現的提示信息,是根據隱藏代碼問題的可能性進行分類的:其中編號400-699指的是被檢查代碼中很可能存在問題而產生的告警信息;編號700-899中出現的信息,產生錯誤的可能性相比告警信息來說級別要低, 但仍然可能是因為代碼問題導致的問題。編號900-999是可選信息,他們不會被默認檢查,除非你在選項中指定檢查他們。
PC-Lint提供了和許多編譯器類似的告警級別設置選項-wLevel和處理函數庫的頭文件的告警級別-wlib(Level),分為以下幾個級別,缺省告警級別為3級:
-w0 不產生信息(除了遇到致命的錯誤)
-w1 只生成錯誤信息 -- 沒有告警信息和其它提示信息
-w2 只有錯誤和告警信息
-w3 生成錯誤、告警和其它提示信息(這是默認設置)
-w4 生成所有信息
PC-Lint的檢查分很多種類,有強類型檢查、變量值跟蹤、語義信息、賦值順序檢查、弱定義檢查、格式檢查、縮進檢查、const變量檢查和 volatile變量檢查等等。
下面將分別介紹PC-Lint常用的,也是比較重要的代碼檢查類型,并舉例介紹了各個檢查類型下可能出現的告警信息以及常用選項的用法:
強類型檢查選項“-strong”和它的輔助(補充)選項“-index”可以對typedef定義的數據類型進行強類型檢查,以保證只有相同類型之間的變量才能互相賦值。
3.2 變量值跟蹤。
變量值初始化跟蹤技術主要是對變量的值的初始化過程進行跟蹤,和其相關的LINT消息主要是644, 645 ("變量可能沒有初始化"), 771, 772 ("不可靠的初始化"), 530 ("未初始化的"), 和1401 - 1403 ("成員 ... 未初始化")。
變量值跟蹤技術從賦值語句、初始化和條件語句中收集信息,而函數的參數被默認為在正確的范圍內,只有在從函數中可以收集到的信息與此不符的情況下才產生告警。與變量值跟蹤相關的消息有:
(1) 訪問地址越界消息(消息415,661,796)
(2) 被0除消息(54,414,795)
(3) NULL指針的錯誤使用(413,613,794)
(4) 非法指針的創建錯誤(416,662,797)
(5) 冗余的布爾值測試(774)
在某些情況下,雖然根據代碼我們可以知道確切的值,但是PC-Lint卻無法獲取所有情況下變量的值的范圍,這時候會產生一些錯誤的告警信息,我們可以使用assert語句增加變量取值范圍信息的方法,來抑制這些錯誤的告警信息的產生。
PC-Lint的函數值跟蹤功能會跟蹤那些將要傳遞給函數(作為函數參數)變量值,當發生函數調用時,這些值被用來初始化函數參數。這種跟蹤功能被用來測定返回值,記錄額外的函數調用,當然還可以用來偵測錯誤。
當一個表達式的值依賴于賦值的順序的時候,會產生告警564。這是C/C++語言中非常普遍的一個問題,但是很少有編譯器會分析這種情況。比如
n++ + n
這個語句是有歧義的,當左邊的+操作先執行的話,它的值會比右邊的先執行的值大一,更普遍的例子是這樣的:
a[i] = i++;
f( i++, n + i );
第一個例子,看起來好像自加操作應該在數組索引計算以后執行,但是如果右邊的賦值操作是在左邊賦值操作之前執行的話,那么自加一操作就會在數組索引計算之前 執行。雖然,賦值操作看起來應該指明一種操作順序,但實際上是沒有的。第二個例子是有歧義的,是因為函數的參數值的計算順序也是沒有保證的。能保證賦值順序的操作符是布爾與(&&)或(||)和條件賦值(? :)以及逗號(,)。
這里的弱定義包含是以下內容:宏定義、typedef名字、聲明、結構、聯合和枚舉類型。因為這些東西可能在模塊中被過多定義且不被使用,PC-Lint 有很多消息用來檢查這些問題。PC-Lint的消息749-769 和1749-1769都是保留用來作為弱定義提示的。
(1) 當一個文件#include的頭文件中沒有任何引用被該文件使用,PC-Lint會發出766告警。
(2) 為了避免一個頭文件變得過于大而臃腫,防止其中存在冗余的聲明,當一個頭文件中的對象聲明沒有被外部模塊引用到時,PC-Lint會發出759告警。
(3) 當變量或者函數只在模塊內部使用的時候,PC-Lint會產生765告警,來提示該變量或者函數應該被聲明為static。